
Introduction
The potential of large language models (LLMs) to tackle complex healthcare challenges continues to draw considerable interest. A recent study, available on arXiv, an open-access platform for scholarly research, examined the performance of GPT-4 on medical challenge problems. By analyzing its results on medical licensing exams, namely USMLE, the study provides important insights into LLMs’ advanced problem-solving and reasoning capabilities in the medical field, highlighting the future of AI in healthcare.
We thoroughly reviewed the entire research paper and distilled its key findings into an easy-to-understand format so you can grasp the essential insights without navigating through extensive technical details.
Methodology
- The model used: The study evaluated the text-only version of GPT-4 (referred to as GPT-4 without vision capabilities) to assess its performance on medical multiple-choice questions (MCQs).
- Datasets used: Two official USMLE datasets from the National Board of Medical Examiners (NBME).
- Prompting strategy: The study employed a standardized prompt structure for both zero-shot and few-shot evaluations. In the few-shot approach, prompts included illustrative examples, whereas zero-shot prompts omitted them entirely. Notably, advanced techniques such as chain-of-thought prompting or retrieval-augmented generation were deliberately excluded.
- Comparison: GPT-4’s performance was compared to its predecessor (GPT-3.5) to all USMLE sample questions studied in the research study.
Results
GPT-4 demonstrated a remarkable improvement over GPT-3.5, achieving an accuracy of approximately 85% on official USMLE exam questions. In contrast, GPT-3.5 averaged around 55%, just shy of the passing threshold required by the USMLE.
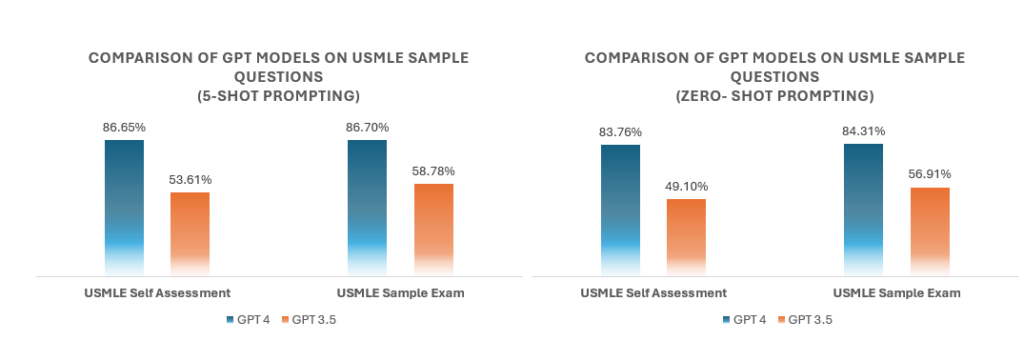
Fig 1: Comparison of GPT models on USMLE sample questions | the future of AI in healthcare.
Why This Matters for the Future of AI in Healthcare
GPT-4’s performance marks a substantial leap in the capabilities of large language models in medical reasoning. With an accuracy of ~85%, GPT-4 not only surpasses the 60% pass threshold required by the USMLE but also achieves results well beyond those of GPT-3.5. This highlights the LLM’s enhanced understanding of medical concepts and reasoning, making it a valuable tool for tackling complex medical problems and advancing AI in medical education.
Benefits for the medical community
The advanced reasoning capabilities of GPT-4 offer great benefits for healthcare professionals and medical students, to name a few:
Clinical Decision Support: Assisting in refining diagnoses, identifying necessary tests, and developing effective treatment plans based on comprehensive patient data.
Medical Education: Providing detailed explanations for errors, thereby helping medical students deepen their understanding and improve their reasoning skills.
Continuous Learning: Keeping practitioners updated with the latest medical research and guidelines, facilitating lifelong learning and optimal patient care.
Conclusion
As LLMs continue to advance, their integration into medical education and practice promises to enhance diagnostic accuracy, streamline treatment planning, and elevate the overall quality of patient care. While acknowledging the current limitations and ethical considerations, the collaboration between AI and medical professionals holds immense potential for the future AI of healthcare. As AI technologies evolve, platforms like Dx will play a pivotal role in bridging the gap between cutting-edge research and practical, everyday medical applications, ultimately contributing to a more informed, responsive, and patient-centric healthcare system.
Read the full research study on arXiv and get started with Dx, an AI-powered search engine designed to support medical professionals in their daily practice
Learn more about how AI is reshaping medical education in our article ,“From Diagnosis to Research: How NUS Medical Students Use AI.”